

Artikel uppdaterad av Joel Lee den 10/10/2017
Lås upp "Top Google Search Keyboard Shortcuts" fuskarket nu!
Detta undertecknar dig till vårt nyhetsbrev
Ange din e-postlåsning Läs vår sekretesspolicyFör många är Google internet. Det är utgångspunkten för att hitta nya webbplatser, och är förmodligen den viktigaste uppfinningen sedan internet själv. Utan sökmotorer skulle nytt webbinnehåll vara otillgängligt för massorna.
Men vet du hur sökmotorer fungerar? Varje sökmotor har tre huvudfunktioner: krypning (för att upptäcka innehåll), indexering (för att spåra och lagra innehåll) och hämtning (för att hämta relevantt innehåll när användarna frågar sökmotorn).
Krypande
Crawling är där allt börjar: förvärv av data om en webbplats.
Det här innefattar skanningsplatser och samlar in information om varje sida: titlar, bilder, nyckelord, andra länkade sidor etc. Olika sökrobotar kan också leta efter olika detaljer, till exempel sidlayouter, där annonser placeras, om länkar är inmatade etc.
Men hur går en webbplats igenom? En automatiserad bot (kallad en "spindel") besöker sida efter sida så snabbt som möjligt, med sidlänkar för att hitta var du ska gå nästa. Även i de tidigaste dagarna kunde Googles spindlar läsa flera hundra sidor per sekund. Numera är det i tusentals.
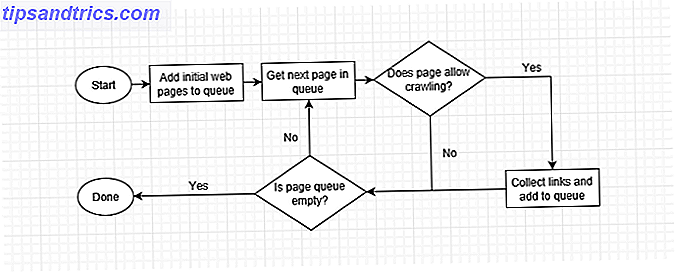
När en webbrobot besöker en sida samlar den varje länk på sidan och lägger till dem i listan över nästa sida att besöka. Det går till nästa sida i listan, samlar länkarna på den sidan och upprepas. Webbrobotrar besöker också tidigare sidor om en gång för att se om det har skett några ändringar.
Det betyder att varje webbplats som är länkad från en indexerad webbplats efterhand kommer att krypts. Vissa webbplatser kryper oftare, och vissa kryper till större djup, men ibland kan en sökrobot ge upp om en webbplatss sidahierarki är för komplex.
Ett sätt att förstå hur en webbrobot fungerar är att bygga en själv. Vi har skrivit en handledning om att skapa en grundläggande webbrobot i PHP, så kolla in om du har någon programmeringsupplevelse.

Observera att sidor kan markeras som "noindex", vilket är som att fråga sökmotorer för att hoppa över indexeringen. Icke-indexerade delar av internet är kända som "deep web" Vad är den djupa webben? Det är viktigare än du tänker på vad är den djupa webben? Det är viktigare än du tror Den djupa vägen och den mörka vägen är både skrämmande och nyfikna, men farorna har blivit överblåst. Här är vad de faktiskt och hur du kan få tillgång till dem själv! Läs mer, och vissa webbplatser, som de som finns på TOR-nätverket, kan inte indexeras av sökmotorer. (Vad är TOR och lökdirigering? Vad är lökruttning, exakt? [MakeUseOf Explains] Vad är lökruttning, exakt? [MakeUseOf Explains] Internet privacy. Anonymitet var en av de största funktionerna på Internet i sin ungdom (eller en av dess värsta egenskaper, beroende på vem du frågar). Lämna bort de typer av problem som kommer fram ... Läs mer)
indexering
Indexering är när data från en krypning behandlas och placeras i en databas.
Föreställ dig att göra en lista över alla böcker du äger, deras förläggare, deras författare, deras genrer, deras sidantal, etc. Crawling är när du kammar genom varje bok medan indexering är när du loggar in dem i din lista.
Tänk nu att det inte bara är ett rum fullt av böcker, men alla bibliotek i världen. Det är en liten version av vad Google gör, som lagrar all denna data i stora datacentraler med tusentals petabyter som är värd för enheter. Minnesstorlekarna förklaras - Gigabyte, Terabytes och Petabytes i Laymans Villkor Minnesstorlekar förklaras - Gigabyte, Terabytes och Petabytes i Laymans villkor Det är lätt att se att 500GB är mer än 100 GB. Men hur jämför olika storlekar? Vad är en gigabyte till en terabyte? Var passar en petabyte in? Låt oss rensa upp det! Läs mer .
Här är en titt inuti ett av Googles sökdatacenter:

Hämtning och rankning
Hämtning är när sökmotorn behandlar din sökfråga och returnerar de mest relevanta sidorna som matchar din fråga.
De flesta sökmotorer differentierar sig genom sina hämtningsmetoder: de använder olika kriterier för att välja och välja vilka sidor som passar bäst med det du vill hitta. Därför varierar sökresultatet mellan Google och Bing och varför Wolfram Alpha är så unikt användbart 10 Coola användningar av Wolfram Alpha Om du läser och skriver i det engelska språket 10 Coola användningar av Wolfram Alpha Om du läser och skriver i det engelska språket Det tog Jag har lite tid att sätta på huvudet kring Wolfram Alpha och de frågor som används för att spruta ut resultaten. Du måste dyka djupt i Wolfram Alpha för att verkligen utnyttja den till ... Läs mer.
Rankingalgoritmer kontrollerar din sökfråga mot miljarder sidor för att bestämma varandras relevans. Företagen skyddar sina rankningsalgoritmer som patenterade industrins hemligheter på grund av deras komplexitet. En bättre algoritm innebär en bättre sökupplevelse.
De vill inte heller att webbdesigners spelar systemet och orättvist klättrar upp i toppen av sökresultaten. Om den interna metoden för en sökmotor någonsin kom ut, skulle alla typer av människor säkert utnyttja den kunskapen till nackdel för sökare som du och jag.

Utnyttjandet av sökmotorer är naturligtvis möjligt men det är inte så lätt längre.
Ursprungligen rankade sökmotorer platser efter hur ofta sökord dykade upp på en sida, vilket ledde till "sökordsstoppning" - fyllning av sidor med nyckelord-tungt nonsens.
Då kom konceptet av länk betydelse: sökmotorer värderade webbplatser med massor av inkommande länkar eftersom de tolkade webbplats popularitet som relevans. Men detta ledde till länk spamming över hela webben. Numera länkar sökmotorerna beroende på "auktoritet" på länkplatsen. Sökmotorer lägger mer värde på länkar från en myndighet än länkar från en länkkatalog.
Idag rankas rankningsalgoritmer i mer mysterium än någonsin tidigare, och "sökmotoroptimering". Demystify SEO: 5 Sökmotoroptimeringsguider som hjälper dig att börja Demystify SEO: 5 Sökmotoroptimeringsguider som hjälper dig att starta Sökmästerskapet tar kunskap, erfarenhet, och massor av försök och fel. Du kan börja lära dig grunden och undvika vanliga SEO-misstag enkelt med hjälp av många SEO-guider som finns tillgängliga på webben. Läs mer är inte så viktigt. Goda sökmotorrangeringar kommer nu från högkvalitativt innehåll och bra användarupplevelser.
Vad är nästa för sökmotorer?
Ah, nu är det en intressant fråga. Svaret är "semantik": meningen med sidans innehåll. Du kan läsa mer om i vår översikt över semantisk markering och dess framtida inverkan Vilken semantisk markering är och hur den kommer att förändra Internet för alltid [Teknologi förklaras] Vilken semantisk markering är och hur den kommer att förändra Internet Forever [Teknologi förklaras] Läs mer.
Men här är kärnan av det.
Just nu kan du söka efter "glutenfria kakor" men resultaten kan returnera recept för glutenfria kakor. Istället kan du hitta vanliga cookie recept som säger "Detta recept är inte glutenfritt." Det har rätt nyckelord, men fel mening.
Med semantik kan du söka efter kak recept och sedan ta bort vissa ingredienser: mjöl, nötter, etc. Du kan också begränsa resultaten till endast recept med prep gånger mindre än 30 minuter och granska poäng på 4/5 eller högre. Det skulle vara coolt, eller hur? Det är där vi är på väg!
Fortfarande förvirrad över hur sökmotorer fungerar? Se hur Google förklarar processen:
Om du tycker det här är intressant kan du också läsa om hur bildsökmotorer fungerar.
Bildkrediter: prykhodov / Depositionfoton